Web scraping with Python
Imagine you need to retrieve a large amount of data from websites and you want to do it as quickly as possible. How would you do it without manually going to each website and getting the data? Well, web scraping is the answer. Web scraping just makes this job easier and faster.
Reading: How to create a website scraper
In this article on Web Scraping with Python, you will briefly learn about web scraping and see a demonstration of how to extract data from a website. I will cover the following topics:
-
-
- Why is web scraping used?
- What is web scraping?
- Is web scraping legal?
- Why is Python good for web scraping?
- How do you scrape data off a website?
- Libraries used for web scraping
- Web scraping example: scraping a Flipkart website
-
Why is web scraping used?
Web scraping is used to collect extensive information from websites. But why does someone need to collect such large amounts of data from websites? To know this, let’s look at applications of web scraping:
- Price comparison: Services like ParseHub use web scraping to collect data from online shopping websites collect and use to compare prices of products.
- Email address collection: Many companies that use email as a marketing medium use web scraping to Collect email ids and then send bulk emails.
- Social Media Scraping: Web scraping is used to collect data from social media sites like Twitter to find out what’s trending.
- Research and development: Web scraping is used to collect a large amount of data (statistics, general information, temperature, etc.) from websites, which is analyzed and used to conduct surveys or for research and development
- Job Opportunities: Job vacancies and interview details are collected from various websites and then listed in one place for easy access by the user.
What is web scraping?
Web scraping is an automated method of extracting large amounts of data from websites. The data on the websites is unstructured. Web scraping helps collect this unstructured data and store it in a structured form. There are different ways to scrape websites like online services, APIs or writing your own code. In this article we will see how to implement web scraping with Python.

Clicking the Inspect tab will open a Browser Inspector Box.
See also: How To Create An Email List From A Google Sheet

Step 3: Find the data you want to extract
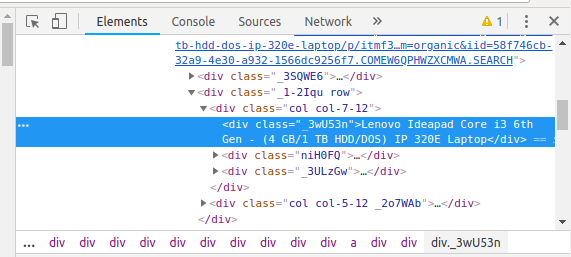
Let’s extract the price, name and rating, each located in the “div” tag.
Step 4: Write the code
First, let’s create a Python file. To do this, open the terminal in Ubuntu and type gedit with the extension .py.
I will name my file “web-s”. Here is the command:
gedit web-s.py
Now let’s write our code in this file.
Let’s first import all the necessary libraries:
from Selenium import webdriver from BeautifulSoup import BeautifulSoup import pandas as pd
To configure webdriver to use the Chrome browser, we need to set the path set to chromedriver
driver = webdriver.Chrome(“/usr/lib/chromium-browser/chromedriver”)
Refer to the following code to open the URL:
products=[ ] #List to store product price name=[] #List to store product price ratings=[] #List to store product rating driver.get(“https://www.flipkart.com/laptops/~buyback-guarantee-on -laptops-/pr?sid=6bo%2Cb5g&uniq”)
See also: How to Select the Best Domain Registrar (Our Recommendations)
Now that we’ve written the code to open the URL, it’s on of time to extract the data from the website. As already mentioned, the data to be extracted is nested in
content = driver.page_source soup = BeautifulSoup(content) for a in soup.findAll(‘a’,href=True, attrs={‘class’:’_31qSD5′}): name= a.find(‘div’, attrs={‘class’:’_3wU53n’}) price=a.find(‘div’, attrs={‘class’:’_1vC4OE _2rQ-NK’}) rating=a.find (‘div’, attrs={‘class’:’hGSR34 _2beYZw’}) products.append(name.text) Prices.append(price.text) reviews.append(rating.text)
Step 5 : Run the code and extract the data
To run the code use the following command:
python web-s.py
Step 6: Save the data in a required format
After extracting the data, you may want to save it in a format. This format varies depending on your needs.For this example, we will save the extracted data in CSV (Comma Separated Value) format. To do this, I add the following lines to my code:
df = pd.DataFrame({‘Product Name’:products,’Price’:prices,’Rating’:ratings}) df.to_csv(‘ products.csv’ , index=False, encoding=’utf-8′)
Now I run the whole code again.
A file named “products.csv” is created and this file contains the extracted data.
I hope you enjoyed this article about web scraping with Python. I hope this blog has been informative and added value to your knowledge. Try web scraping now. Experiment with different Python modules and applications.
To gain in-depth knowledge of the Python programming language and its various applications, register here for the live online Python Online Course with 24/7 support and lifetime access login.
See also: Add Files or Folders to ZIP Archives Programmatically in C
.