Bạn đang quan tâm đến Mọi Người Sử Dụng Kaggle Là Gì, Mọi Người Sử Dụng Kaggle Như Thế Nào phải không? Nào hãy cùng VCCIDATA đón xem bài viết này ngay sau đây nhé, vì nó vô cùng thú vị và hay đấy!
XEM VIDEO Mọi Người Sử Dụng Kaggle Là Gì, Mọi Người Sử Dụng Kaggle Như Thế Nào tại đây.
Kaggle là một cộng đồng tuyệt vời của những nhà khoa học dữ liệu. Cá nhân tôi cũng có một thời gian trải nghiệm và tham gia các cuộc thi trên này. Tôi học được từ những người chơi ở kaggle về các kĩ thuật và cách xử lý nhiều hơn tất cả những gì tôi học được trước đó. Tuy nhiên, sau một thời gian, tôi quyết định dành ít thời gian trên kaggle hơn thay vì tham gia sâu vào các cuộc thi như trước.
Đang xem: Kaggle là gì
Có một số lý do để tôi đưa ra quyết định này.
Tiêu chí đơn giản
Các bạn hẳn đã quen thuộc với hàm mục tiêu trong machine learning. Các cuộc thi trên kaggle cũng chỉ có một mục tiêu duy nhất đó là tối thiểu hóa giá trị của loss function.


Việc tối thiểu hàm mục tiêu là đúng, nhưng chưa đủ. Trong thực tế ngoài quan tâm tới khả năng dự đoán của mô hình, chúng ta còn phải quan tâm tới khả năng triển khai mô hình đó, khả năng tương thích với hệ thống hiện tại, thời gian tính toán, khả năng giải thích… Những tiêu chí này hoàn toàn không được đưa vào tiêu chí của các cuộc thi trên kaggle.
Hãy lấy ví dụ về thuật toán gợi ý giành chiến thắng trong cuộc thi mà Netflix tổ chức.
A year into the competition, the Korbell team won the first Progress Prize with an 8.43% improvement. They reported more than 2000 hours of work in order to come up with the final combination of 107 algorithms that gave them this prize.
Well, đây là một thuật toán tốt, nhưng hãy tưởng tượng bạn sẽ áp dụng thuật toán này như thế nào cho số lượng rating, user ngày càng tăng? Nó quá phức tạp để đưa vào ứng dụng.
Tập trung vào engineering
Điều này có một phần lý do bởi sự đơn giản của tiêu chí bên trên. Các công thức chiến thắng cuộc thi trên kaggle dần dần trở nên khá tiêu cực: Nhiều feature, nhiều model, ensemble chúng lại. Nếu điều này không giúp bạn tăng thứ hạng? Sử dụng năng lực tính toán để sử dụng nhiều feature hơn, nhiều model hơn. Điều này không khác gì chúng ta cố gắng xây dựng một blackbox to đùng và cầu mong chúng cho kết quả tốt.
Hãy lấy ví dụ về cuộc thi home credit.
Xem thêm: Chuyển Phát Nhanh J&Amp;T – Chuyển Phát Nhanh J&T Chi Nhánh Quảng Nam

Với cá nhân tôi, một người từng làm trong lĩnh vực ngân hàng — tài chính, tôi kì vọng có nhiều kernel mang lại insight thú vị về hành vi vay và chi tiêu của khách hàng thay vì pipeline với một loạt feature và mô hình như bên trên.
Với riêng cuộc thi của home credit, cá nhân tôi thấy rằng roc-auc = 0.81 là rất tốt và không có khả năng cao hơn nữa. Các phương pháp như tăng thêm feature, thêm mô hình… để kì vọng tăng thêm 0.1 điểm nữa chỉ là cầu may.
Lý do là gì? Tôi đã debug mô hình và phân tích dữ liệu, đến một ngưỡng bạn sẽ không thể phân biệt được về mặt dữ liệu sự khác nhau của một khoản vay default và non-default. Với các features hiện tại, mô hình cũng không quá chắc chắn về dự đoán trong việc phân loại. Vì vậy, các nỗ lực cần thiết nên tập trung vào việc thu thập thêm các features mạnh thay vì tăng độ phức tạp của mô hình. Nhà khoa học dữ liệu, khi đó, cần dựa vào sự quan trọng của biến số đối với chất lượng phân loại của mô hình để gợi ý về những thông tin cần thu thập thêm.
Thuật toán trên kaggle không mới
Thực ra những thuật toán mới sẽ ra đời ở những bài báo khoa học. Kaggle chỉ là nơi áp dụng và kiểm chứng xem các thuật toán này có hữu dụng không trong thực tế.
Vì vậy, hiện tại tôi hài lòng với một số cách tiếp cận hiệu quả mà mình biết đối với từng bài toán và chỉ coi kaggle là nơi tham khảo các kĩ thuật thực hành bổ sung. Một số bài toán và thuật toán mà tôi cho rằng nên sử dụng:
Đối với bài toán phân loại với input là tabular data: tree bagging và tree boosting. Nếu bạn muốn mô hình có thể diễn giải, hãy chọn tree bagging. Nếu muốn chất lượng dự đoán, tree boosting là lựa chọn hợp lý.Bài toán hồi quy với input là tabular data: fully connected net hoặc tree boosting đang làm rất tốt.Bài toán dự đoạn chuỗi thời gian: RNN có thể xử lý được vấn đề.Đối với bài toán phân loại văn bản, hình ảnh: transfer learning đang mang lại kết quả rất tốt.
Thắng một cuộc thi trên kaggle không giúp ích nhiều cho công việc của tôi
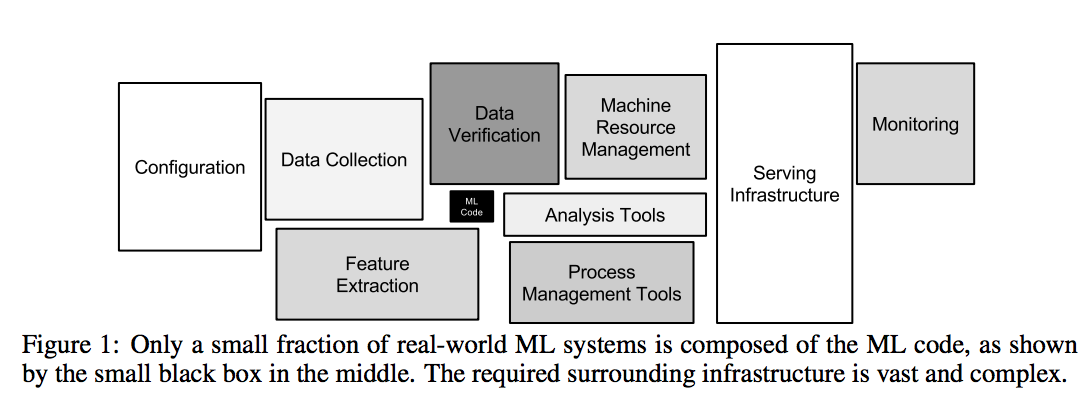
Source: From the paper “Hidden Technical Debt in Machine Learning System” by D. Sculley et al
Như bạn thấy ở hình bên trên, hành trình của dữ liệu từ khi sinh ra cho tới khi có được một insight có ích cần rất nhiều công đoạn và công sức. Khi đã có được một bộ dữ liệu sạch đẹp thì việc training mô hình để có được dự đoán đủ tốt ban đầu (theo cá nhân tôi) là không quá khó. Việc thắng một cuộc thi trên kaggle chỉ chứng minh rằng tôi giải quyết được một phần rất nhỏ trong các bước trên. Vì vậy nó không giúp ích quá nhiều cho công việc của tôi.
Hãy dành thời gian cho những thứ quan trọng khác
Người làm về dữ liệu ngoài hiểu biết về công cụ, ngôn ngữ lập trình hay thuật toán machine learning còn phải tốt rất nhiều kĩ năng mềm khác như hiểu biết về ngành, kĩ năng giao tiếp, kĩ năng thuyết trình, kĩ năng đặt câu hỏi, kĩ năng phân tích vấn đề…
Vì vậy, hãy chắc chắn rằng bạn dành thời gian để cải thiện tất cả các kĩ năng cần thiết thay vì quá tập trung vào công cụ, ngôn ngữ hay thuật toán.
Xem thêm: mua vòng tay nam
Sau tất cả
Kaggle vẫn rất tuyệt!
Những gì tôi học được về data science từ kaggle là rất nhiều. Tuy nhiên các cuộc thi trên kaggle chỉ phản ánh một phần rất nhỏ những gì trong thực tế công việc của những người làm về dữ liệu. Vì vậy, hãy dành thời gian và sự quan tâm hợp lý trên kaggle để có thời gian hoàn thiện tốt tất cả kĩ năng của mình.
Vậy là đến đây bài viết về Mọi Người Sử Dụng Kaggle Là Gì, Mọi Người Sử Dụng Kaggle Như Thế Nào đã dừng lại rồi. Hy vọng bạn luôn theo dõi và đọc những bài viết hay của chúng tôi trên website VCCIDATA.COM.VN
Chúc các bạn luôn gặt hái nhiều thành công trong cuộc sống!
